
If you are a language enthusiast, you may often be thinking about how German is similar to English or what similarities exist between German and Swedish. Germanic languages obviously have a wide range of very similar grammatical constructs, not to mention very similarly used tenses, which I am sure is a subject of very intense discussion among comparative linguists at various language faculties, but I have the impression that it has never been quantified and only talked about. So let’s try to answer this question with some data.
But how to measure it?
One of the methods to estimate the similarity between two text strings is the method called Levenstein distance. It is a measure of the similarity between two strings by calculating the minimum number of single character edits (insertions, deletions, or substitutions) required to change one string into the other.
For the sake of this small kind of research, I collected a total of about 110 sentences of texts available in English, German, Swedish, Norwegian, Danish, Dutch, Afrikaans, and in Icelandic.
Of course, the results won’t tell you much about grammar or phonetics, but they will tell you about lexical similarities.
Are you ready?
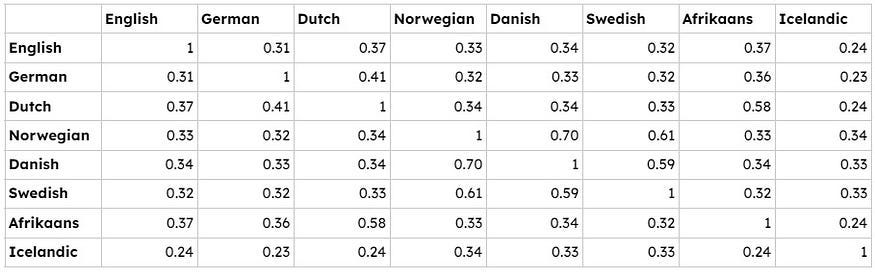
If we measure the average of the distances between the examined text strings, we get the following results:
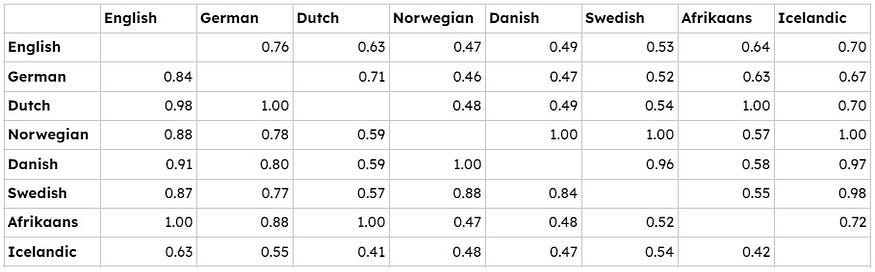
If we scale it to look at the language that is closest to the one in the header, it will look something like this:
What does this tell us?
The closest language to English is Afrikaans, the closest language to German is Dutch, the closest language to Dutch is Afrikaans and vice versa (what a surprise😀), the closest language to Norwegian is Danish and vice versa, the closest language to Swedish is Norwegian, and the closest language to Icelandic is Norwegian.
Surprised? Having the results at hand, it is pretty much explained by either history or geography.
Which Germanic language is most like English?
According to this simple analysis, the closest language to English is Afrikaans, followed by Dutch and Danish. But I guess we would need a large sample to make it statistically more significant.
Does this analysis has any limitation?
Yes, of course it does. It may differ slightly from reality for various reasons, as the selected texts may not be representative of all language usage, but it gives us a data-driven answer. And there are some other languages left out of this analysis, such as Frisian, Irish, Scottish Gaelic, or Welsh.